Digital Immunization Passport has been selected as one of the brightest data portability projects in Europe

OwnYourData and the Human Colossus Foundation have been selected to take part in the Data Portability & Services Incubator (DAPSI), a 3-year EU funded project that empowers internet innovators to develop new solutions in the data portability field.
What is DAPSI?
The Data Portability and Services Incubator (DAPSI) is a EU funded project, under the European Commission’s Next Generation Internet (NGI) initiative, to empower top internet innovators to develop human-centric solutions, addressing the challenge of personal data portability on the internet, as foreseen under the GDPR and make it significantly easier for citizens to have any data which is stored with one service provider transmitted directly to another provider.
DAPSI will support top-notch projects through a 9-month incubation programme where experts in diverse fields will provide a successful working methodology, access to top infrastructure, training in business and data related topics, coaching, mentoring, and a vibrant ecosystem. On top of that, each DAPSI project can receive up to €150k equity-free funding.
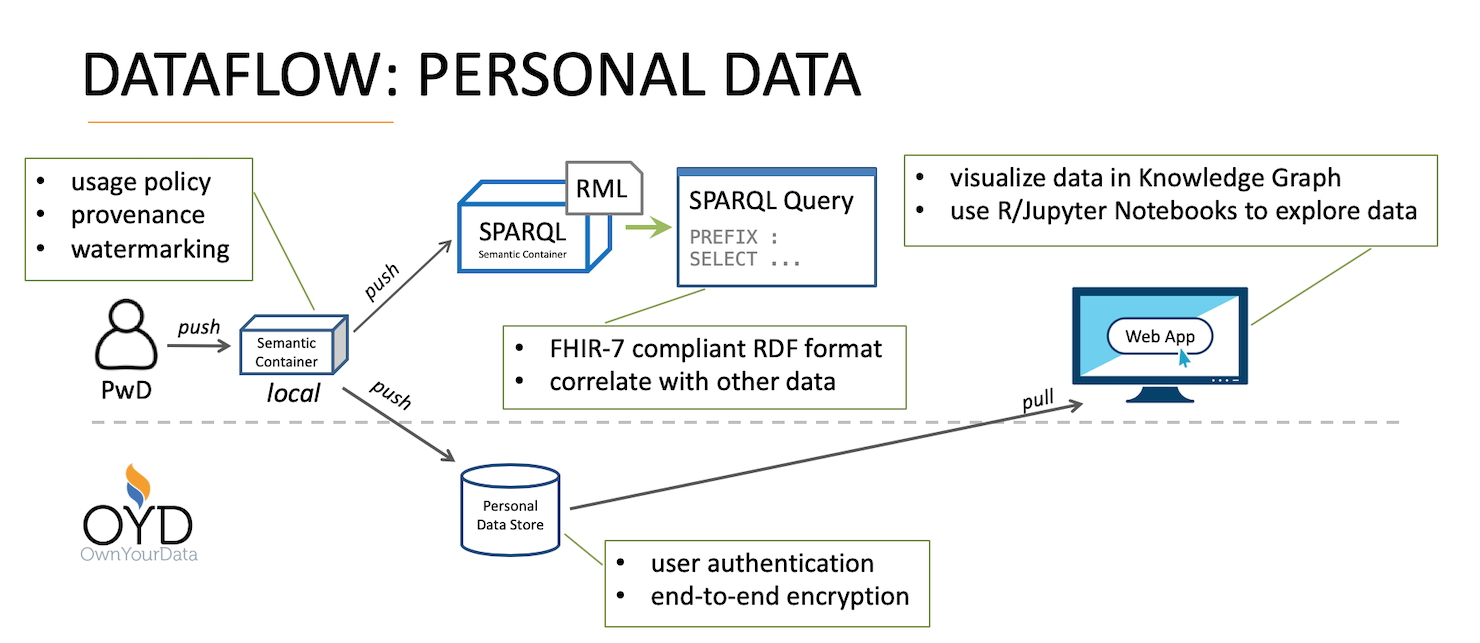
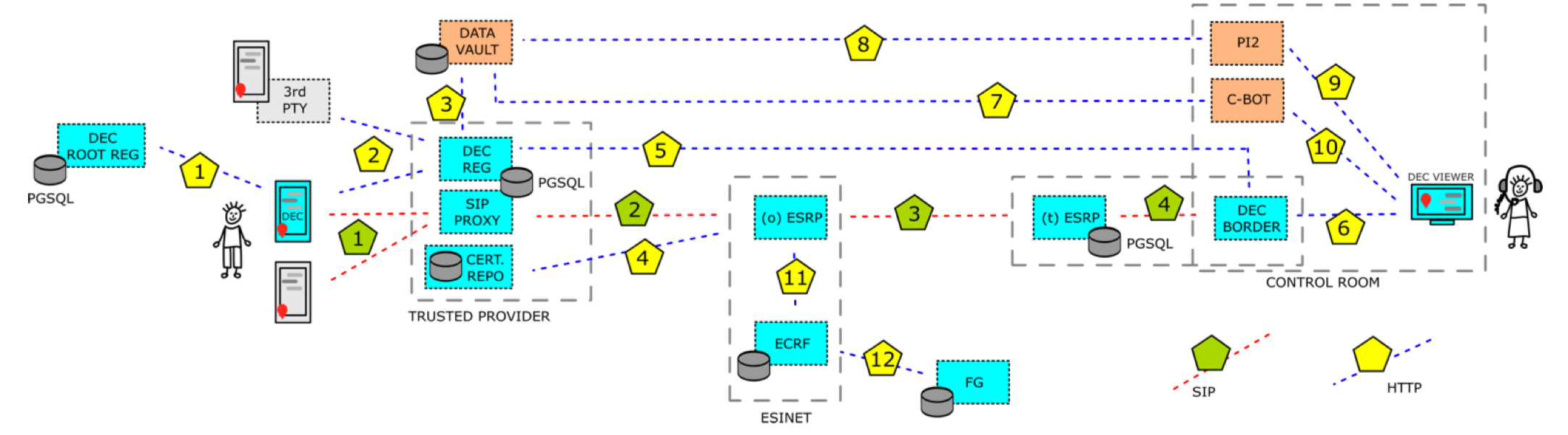
Digital Immunization Passport (DIP) is taking part in DAPSI to create a state-of-the-art digital certificate of vaccination. Currently, vaccination and immunization information are spread over different organizations like labs and hospitals as well as pharmaceutical companies together with government agencies. A patient usually only has a paper certificate that provides vaccination treatments with often difficult to read handwritten additional information. In the proposed solution OwnYourData and Human Colossus Foundation will develop an end-to-end data flow that:
- connects to various immunization information providers,
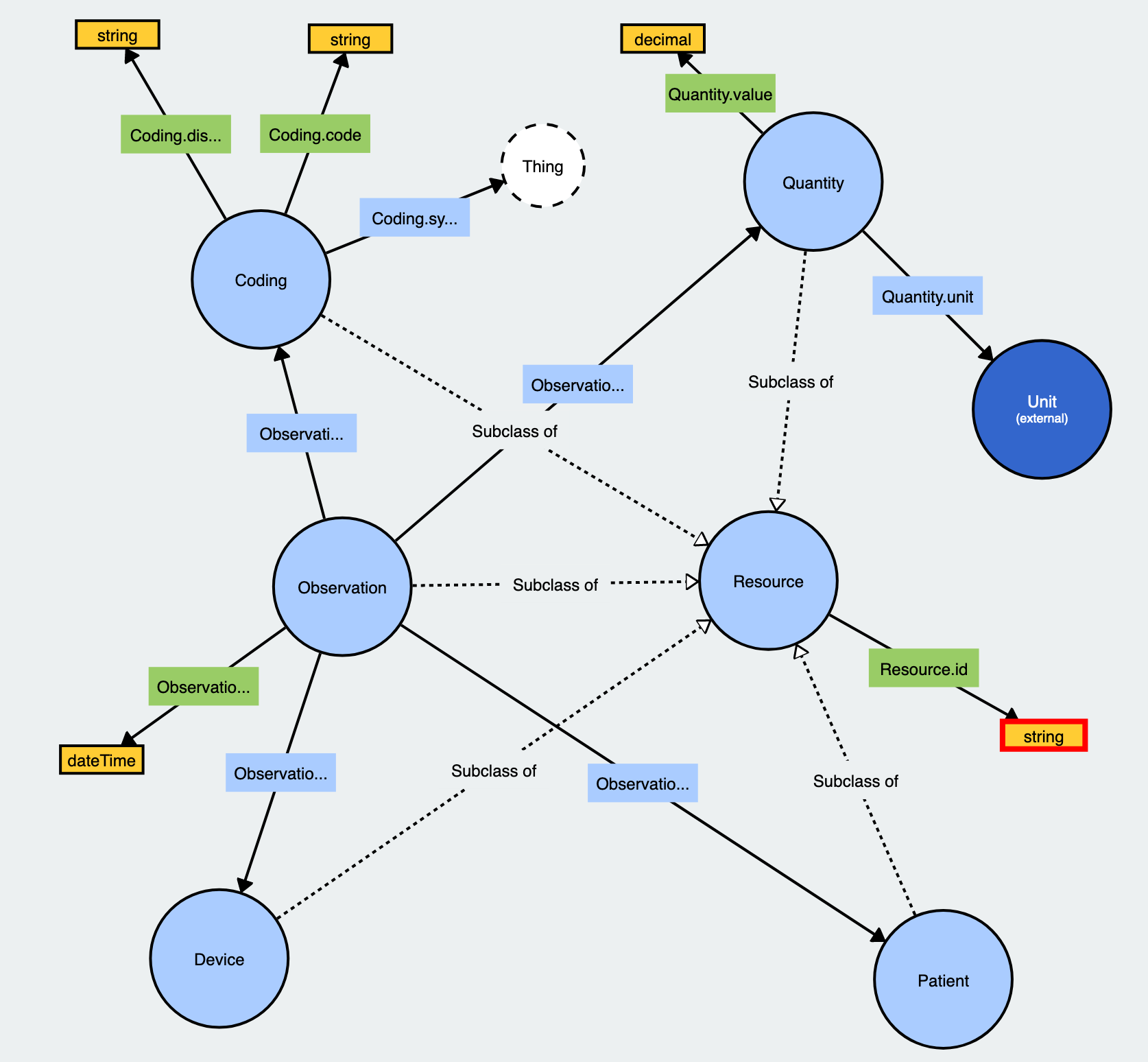
- aggregates, harmonizes, and semantically annotates the data,
- makes this data-set available in an open format accessible for Personal Data Stores (PDS), compliant to the MyData Operator guidelines,
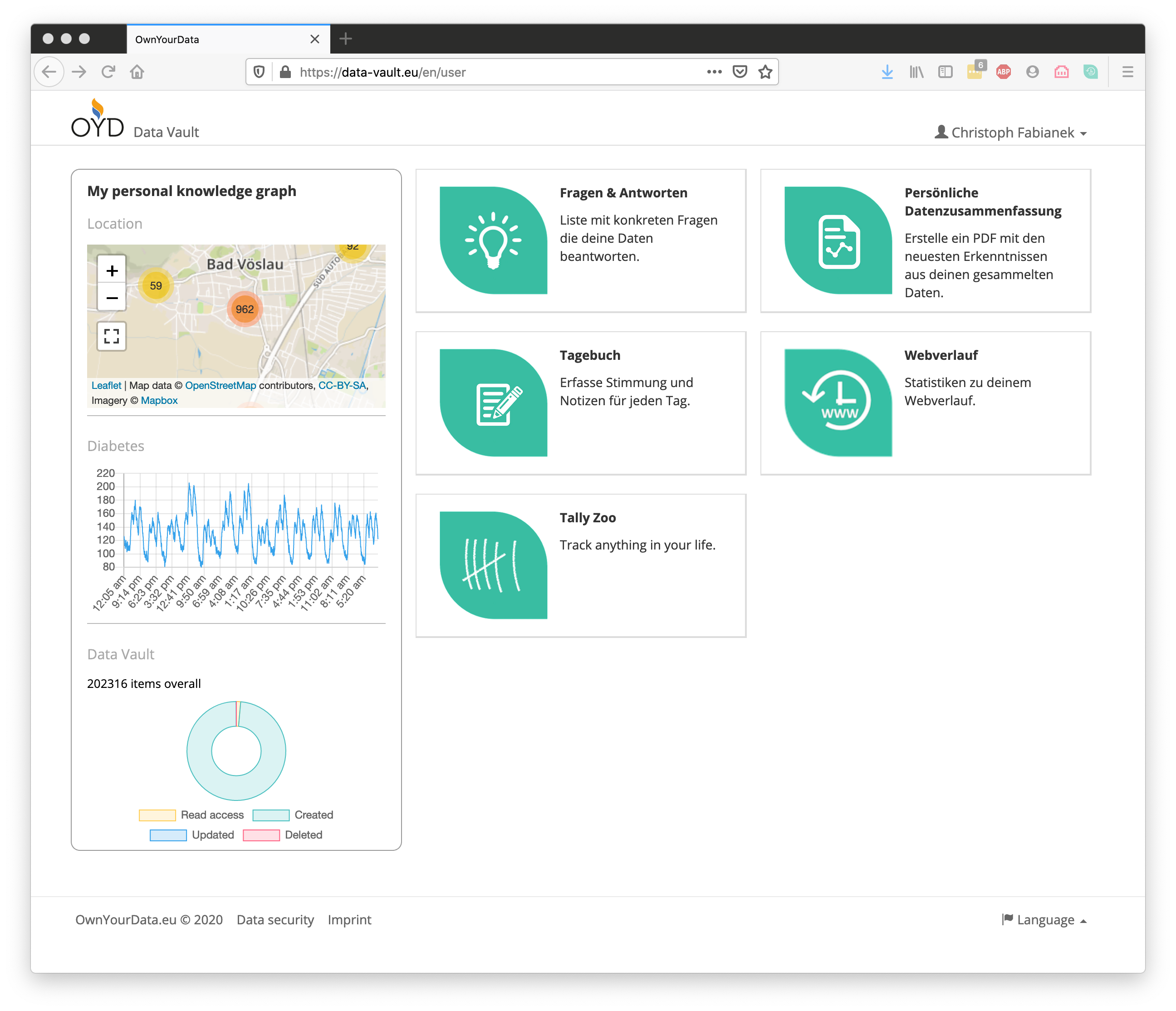
- provide a human-centric data management platform for health information,
- allows to prove immunization status through Verifiable Credentials, and
- packages selected health data for processing by 3rd parties together with a well-defined usage policy and a provenance trail.
The main focus of this project is on Data Interoperability & Compatibility through establishing interfaces between health industry and individuals as well as pushing forward on standardized interfaces for PDSs. Additionally, we address Data Transparency (Usage Policies and Data Provenance in Semantic Containers) and Security & Privacy (by applying blockchain technology and digital watermarking on data sharing).
How does it work?
In the two-phase supporting programme, the projects will develop advanced solutions in the Data Portability field. From September 2020 to February 2021 (Kick-Start phase) they will develop a solution related to a specific use case. The best projects will progress to the second phase (Booster) where the use cases will be fostered to evolve into solid projects to gain enough traction for deployment and get ready for the market.
Follow our journey through DAPSI!
Take a look at the DAPSI project portfolio to see more information about the selected innovators. The Digital Immunization Passport page is available here.
To read more about DAPSI, please visit the website: dapsi.ngi.eu

 Personium and OwnYourData are proud to announce a partnership for collaborating in Personal Data Store interoperability.
Personium and OwnYourData are proud to announce a partnership for collaborating in Personal Data Store interoperability.
