Projektabschluss IDunion
Dieser Tage geht das FFG-geförderte IDunion Projekt zu Ende und in diesem Blogbeitrag fassen wir die dabei erreichten Ergebnisse zusammen.
Dieser Tage geht das FFG-geförderte IDunion Projekt zu Ende und in diesem Blogbeitrag fassen wir die dabei erreichten Ergebnisse zusammen.
Im Zuge des FFG-geförderten Projekt IDunion wurde von OwnYourData unter anderem ein Login ohne Passwort auf Basis von OpenID Connect für Semantic Container und Data Vault implementiert. Das esatus Wallet stellt dabei die Autorisierungsebene zur Verfügung.
![]()
Eine neue Initiative zur Gestaltung des zukünftigen Umgangs mit persönlichen Daten ist da – der MyData Operator 2020 Status wurde OwnYourData verliehen.
Im Juli 2020 wurde OwnYourData mit dem Status „MyData Operator 2020” ausgezeichnet. Der Preis wurde an 16 weltweit führende Organisationen aus 12 Ländern vergeben, die sich alle für menschenzentrierte Ansätze für personenbezogene Daten einsetzen.
Ein MyData Operator, wie im Whitepaper „Grundlegendes zu MyData Operators“ (Understanding MyData Operators) beschrieben, ist ein Anbieter von Infrastruktur für die Verwaltung personenbezogener Daten und ein Schlüsselelement bei der Schaffung nachhaltiger Ökosysteme für einen fairen und ethischen Umgang mit personenbezogenen Daten. MyData Operator bieten Interoperabilität auf technischer, informativer und Governance-Ebene, um den Fluss personenbezogener Daten zwischen Diensten zu unterstützen. Sie sind Beispiele für einen menschenzentrierten Ansatz für das, was die jüngste EU-Datenstrategie als „ neuartige neutrale Vermittler im Wirtschaftszweig der personenbezogenen Daten“ bezeichnet und die eine entscheidende Rolle bei der Bereitstellung der Vision der Strategie von Datenräumen spielen werden.
Radikale Zusammenarbeit für eine menschenzentrierte Datenkontrolle
Die ausgezeichneten Organisationen arbeiten mit ihren Mitbewerbern in Bereichen von beiderseitigem Interesse zusammen, um ein erfolgreiches, interoperables Ökosystem für personenbezogene Daten zu schaffen. „MyData Global gratuliert den Preisträgern zu ihrer Integrität, ihrem Engagement und ihrer Offenheit für diesen beispiellosen Informationsaustausch, der weit über die Anforderungen einer Vorschrift hinausgeht. Letztendlich sind es die einzelnen Personen, die von diesem gemeinsamen Verständnis der MyData Operator profitieren werden – mit mehr Transparenz, besseren Auswahlmöglichkeiten und innovativeren, verantwortungsbewussteren Diensten“, erklärt Joss Langford, Co-Leiter der MyData Operators Thematic Group und leitender Redakteur des Whitepaper zu MyData Operators.
Weitere Information
Die Organisationen, die den Status MyData Operator 2020 erhalten haben, sind hier aufgelistet: mydata.org/operators/
Der MyData Operator 2020 Award wurde von der international anerkannten gemeinnützigen Organiation MyData Global ins Leben gerufen. Mit der Auszeichnung werden Organisationen ausgezeichnet, die die Person in den Mittelpunkt ihrer persönlichen Daten stellen, Tools zur Verwaltung personenbezogener Daten bereitstellen und die Person als Hauptnutznießer dieser Daten haben.
Zertifikat der Auszeichnung

Das Projekt DECTS (Deaf Emergency Chat and Training System) hat das Ziel Gehörlosen-Notrufe und eine dazugehörige Trainingsumgebung in mehreren Sprachen bereitzustellen. Mit Hilfe eines Chatbots können gehörlose Personen den Umgang mit der App lernen und erzeugen dabei gleichzeitig Testdaten zur Schulung des Leitstellenpersonals. Die Benutzer können festlegen, ob die Eingaben als Testdaten verwendet werden und es erfolgt die Dokumentation über Herkunft, DSGVO konforme Bereitstellung und Nutzung der Daten. Ebenfalls kann die Zustimmung über die Verwendung der Daten nachträglich geändert und widerrufen werden.
Zur Umsetzung arbeiten die Teams von OwnYourData und DEC112 zusammen. In früheren Projekten wurde bereits eine Infrastruktur in Österreich für Gehörlosen-Notrufe aufgebaut und die Herausforderung liegt nun im internationalen Betrieb – etwa wenn ein österreichischer Tourist in Kopenhagen auf Urlaub ist: Hier gilt es Notrufe einer in Österreich registrierten DEC112 App an die Leitstelle in Kopenhagen zu vermitteln.
Für die Trainingsumgebung wurde ein Chatbot entwickelt der eine Leitstelle simuliert. Bei einem Test-Chat werden strukturiert Informationen abgefragt und anhand bestimmter Stichwörter ergeben sich weitere Fragen. In Zusammenarbeit mit Notrufzentralen wurden typische Gesprächsverläufe analysiert und daraus sogenannte Entscheidungsbäume erstellt, die der Chatbot automatisch abarbeitet.
Stimmt ein Benutzer der weiteren Verwendung des Chatprotokolls zu, kann diese Zustimmung im OwnYourData Datentresor verwaltet werden. Dort wird die Zustimmung der Weitergabe der Daten dokumentiert und es ist möglich abzufragen, wann auf die Daten zugegriffen wurde. Insbesondere kann aber auch der Zugriff eingeschränkt oder nachträglich untersagt werden. Als Technologie-Plattform kommen dabei Semantic Container zum Einsatz, welche Datenzugriffe transparent und nachvollziehbar sicherstellen.
Und schließlich können im OwnYourData Datentresor auch persönliche Daten (Notrufkontakte, medizinische Daten und weitere Informationen) hinterlegt werden, welche im Fall eines tatsächlichen Notruf-Chats der Leitstelle automatisch bereitgestellt werden. Die Adressierung dieser persönlichen Daten erfolgt über eine DID (Decentralized ID) und die Daten selbst verschlüsselt abgespeichert. Durch das Shamir‘s-Secret-Sharing-Verfahren wird dabei sichergestellt, dass die Daten nur vom Benutzer und der Leitstelle gelesen werden können, aber weder OwnYourData noch DEC112 Zugriff haben können.
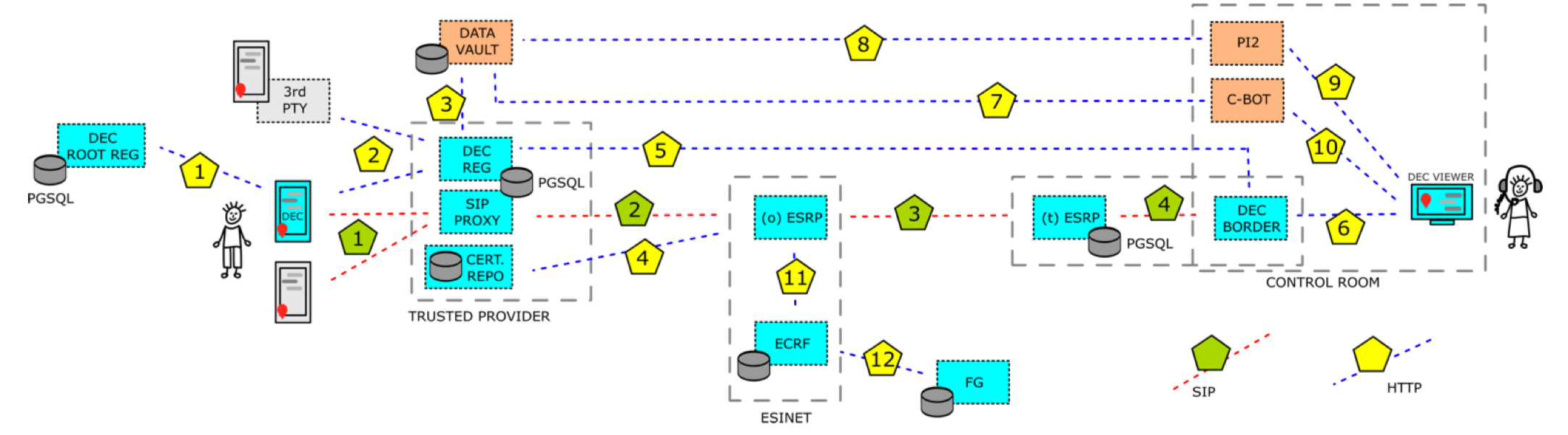
In der Grafik ist die System-Architektur für das Projekt abgebildet, samt den Datenströmen zwischen den einzelnen Komponenten. Alle Teile stehen inzwischen zumindest als Prototyp zur Verfügung und im Mai fanden auch schon die ersten Ende-zu-Ende Tests statt.
Am Beginn eines Projekts ist es eine gute Idee sich detailliert die Frage zu stellen Warum man dieses Vorhaben durchführt. Und da ich auch immer wieder gefragt werde: „Warum soll ich eigentlich OwnYourData verwenden und meine Daten sammeln?“ möchte ich in diesem Blogpost diese Frage zuerst einmal aus meiner Perspektive beantworten.
Ich verwende gerne die unterschiedlichsten Online-Services: natürlich Email, aber auch Fitness Tracker, ich habe eine online Finanzverwaltung und ich nutze verschiedene Social Media Sites; viele meiner Dateien sind in einem Online-Speicher abgelegt; ich mache mir unzählige Notizen und vertraue darauf, dass ich diese Informationen auf allen Geräten an jedem Ort zur Verfügung habe; und das ist nur ein Teil der Dienste die ich jeden Tag ganz selbstverständlich verwende. Nach Wikileaks und Snowden habe ich dann sichergestellt, dass die meisten Daten verschlüsselt abgelegt sind (wo möglich) und dass ich 2-Faktor Authentifizierung verwende (wenn angeboten). Aber das geht mir noch nicht weit genug.
Speichern zu meinen Bedingungen
Wie oben schon aufgezählt sind Daten weit verstreut gespeichert. Ich möchte aber alle meine Daten an einem Ort meiner Wahl (online oder bei mir daheim) speichern und ständigen Zugriff auf die vollständige Historie dieser Daten haben. Ich will mir keine Sorgen machen, dass ein Anbieter ein Service morgen abdreht und meine Daten nicht mehr vorhanden sind, oder durch eine Änderung der Nutzungsbedingungen der Zugriff auf meine Daten plötzlich kostenpflichtig wird. Und ich möchte eine einheitliche Schnittstelle auf diesen Datenspeicher, um mit dem Werkzeug meiner Wahl darauf zugreifen zu können.
Selbstbestimmt eigene Daten verwenden
Alle Online-Dienste die ich verwende bieten eine gute Benutzeroberfläche, sind optimiert für die jeweilige Aufgabe und bieten (meistens) passable Auswertungen für spezielle Fragestellungen die sich aus der Verwendung ergeben. Wenn ich aber meine Fitnessdaten mit meinem Kalender verbinden möchte, habe ich keine Chance. Gibt es eine Verbindung zwischen meinen Social Media Konsum und den Büchern und Artikeln die ich lese? Das ist für mich schwierig herauszufinden, obwohl die angezeigten Werbungen im Onlinehandel genau hier einen Zusammenhang zu erkennen scheinen.
Und ich bin neugierig. Ich möchte in meinem Bekanntenkreis „Experimente“ durchführen und Daten anonymisiert vergleichen. Immer öfter gibt es Studien – vor allem im medizinischen Bereich – an denen ich gerne teilnehmen würde und dort meine Daten „spenden“. Und wenn es möglich ist Daten kontrolliert weiterzugeben, würde es mich zumindest interessieren, ob und zu welchem Preis ich bestimmte Daten von mir verkaufen kann.
Nutzen
Ziel von OwnYourData ist es nun eine solche selbstbestimmte Speicherung und Verarbeitung von Daten zu ermöglichen. Neben diesen verschiedenen Anwendungsbereichen ist für mich ist die Sammlung all dieser Daten auch eine eigene Standortbestimmung – was weiß ich über mich? Und aus dem Wissen, ergeben sich eine Fülle von Möglichkeiten die sich eröffnen bzw. auch ausgeschlossen werden. Bei meiner aktuellen Kondition und 3 kleinen Kindern wird sich das Training für einen (Halb-) Marathon kaum ausgehen (oder nur, wenn ich alle meine anderen Aktivitäten einstelle).
Durch diese Selbstreflektion und der konkreten Entscheidung was ich mache, definiert sich auch, wie konsequent und erfolgreich ich in meinem Tun bin. Jeden Tag stehen wir vor einer Fülle von Möglichkeiten und gerade im Online-Bereich wird uns ständig suggeriert, noch mehr und noch länger jedes Angebot zu nutzen. Dabei wird es immer wichtiger zu entscheiden, was wir nicht tun und ein klares Ziel hilft am besten bei der Entscheidung für oder wider einer Sache.
Zusammenfassung
Es gibt verschiedene Gründe, warum man Daten über sich sammeln möchte. Vielleicht will man seine Zeit besser planen, die Finanzen im Griff haben oder man hat eine konkrete Frage bei seiner Gesundheit. Klar ist, dass man nur optimieren kann, was man auch misst.
Unsere Zeit hat es mit sich gebracht, dass sehr viele Messdaten aus dem alltäglichen Leben verfügbar sind. Wir müssen uns nur trauen, diese Datenquellen zu erschließen, um selbst davon zu profitieren. Und das möchte OwnYourDate jeder und jedem ermöglichen.
Auch dieses Jahr hat sich OwnYourData wieder um Förderungen zur Weiterentwicklung der bestehenden Lösung beworben. Konkret haben wir dabei um eine Folgeantrag bei der Netideeund um den Kreativwirtschaftscheck des AWS angesucht. Beide Anträge wurden positiv bewertet und wir freuen uns sehr, mit dieser finanziellen Unterstützung die Ziele von OwnYourData schneller umsetzen zu können.
 Zusammen mit der Verleihung der Netidee-Förderung fand auch ein 2-tägiges Community Camp statt. Dabei wurden die eingereichten Projekte aus den unterschiedlichsten Perspektiven beleuchtet und durch Mentoren unterstützt. Am Ende konnten die Teilnehmer ihre Projekte in Form eines 3-minütigen Pitches präsentieren und es fand ein Community Voting statt. Dabei machte OwnYourData den 2. Platz! Hier ist ein Artikel darüber im Brutkasten.
Zusammen mit der Verleihung der Netidee-Förderung fand auch ein 2-tägiges Community Camp statt. Dabei wurden die eingereichten Projekte aus den unterschiedlichsten Perspektiven beleuchtet und durch Mentoren unterstützt. Am Ende konnten die Teilnehmer ihre Projekte in Form eines 3-minütigen Pitches präsentieren und es fand ein Community Voting statt. Dabei machte OwnYourData den 2. Platz! Hier ist ein Artikel darüber im Brutkasten.
Dazu auch gleich ein Hinweis: Die Ziele der Netidee-Folgeförderung) sowie in Zukunft auch Statusberichte zum Projekt werden am Netidee-Blog veröffentlicht und sind ab jetzt auf der zugehörigen OwnYourData-Seite zu finden: https://www.netidee.at/ownyourdata-20. Die Projektdauer für diese Förderung von Netidee läuft über das ganze Jahr 2018.
 Ebenfalls ein wichtiger Schritt für uns ist die Förderung durch den Kreativwirtschaftscheck vom AWS. Konkret soll es darum gehen, wie Benutzer möglichst einfach Datenquellen erschliesen und selbst Daten sammeln können. Die Ergebnisse hoffen wir bis Mai 2018 präsentieren zu können.
Ebenfalls ein wichtiger Schritt für uns ist die Förderung durch den Kreativwirtschaftscheck vom AWS. Konkret soll es darum gehen, wie Benutzer möglichst einfach Datenquellen erschliesen und selbst Daten sammeln können. Die Ergebnisse hoffen wir bis Mai 2018 präsentieren zu können.
Mit diesen Förderungen als Rückenwind planen wir spannende neue Features in den kommenden Monaten. Hol dir schon jetzt deinen eigenen Datentresor und profitiere von deinen gesammelten Daten!
 Im Sommer nahm ich an der Keystone Training School teil und seitdem beschäftige ich mich mit dem Thema Linked Data. Im Zuge dessen lernte ich das Linked Data Lab der TU Wien kennen und das dort entwickelte Projekt der Linked Widgets. Dieses Projekt ermöglicht durch sogenannte Mashups Datenquellen zu erschließen, miteinander zu verbinden und schließlich zu visualisieren.
Im Sommer nahm ich an der Keystone Training School teil und seitdem beschäftige ich mich mit dem Thema Linked Data. Im Zuge dessen lernte ich das Linked Data Lab der TU Wien kennen und das dort entwickelte Projekt der Linked Widgets. Dieses Projekt ermöglicht durch sogenannte Mashups Datenquellen zu erschließen, miteinander zu verbinden und schließlich zu visualisieren.
Klicke auf das nebenstehende Bild um ein Beispiel dafür anzuzeigen! (Dabei werden Daten aus 2 Google Sheets ausgelesen, miteinander kombiniert, gefiltert, die Summen gebildet und schließlich als Balkendiagramm angezeigt; zum Darstellen der Visualisierung klicke auf das „Play“ Symbol im letzten Kasten.)
Für OwnYourData sollen Apps in Zukunft die gesammelten Daten als Local Widget (das sind die blau dargestellten Kästchen, welche lokal im Browser ausgeführt werden können) bereitstellen. In einem ersten Schritt werden Daten aus der Raumklima App Sensor Werte als Linked Data bereitstellen und mann kann diese dann zB mit dem Google Chart Widget anzeigen.
Ein weiterer interessanter Anwendungsfall ist aus meiner Sicht die Möglichkeit eine solche Kaskade aus Verarbeitungsschritten zu speichern und dann nur das Ergebnis in eine Webseite einzubinden. So ist es denkbar, personalisierte Texte und Grafiken basierend auf gesammelten Daten im eigenen Datentresor darzustellen.
Welche Ideen hast du für die Verwendung persönlicher Daten und wie können diese Ideen mit Linked Widgets umgesetzt werden? Schreibe uns und gerne versuchen wir deine Vorschläge umzusetzen!
Eine wichtige Grundvoraussetzung bei der Verwendung von OwnYourData ist die Einfachheit der Bedienung. Deshalb haben wir uns Gedanken gemacht, wie wir vorhandene Apps weiter verbessern und vor allem vereinfachen können. Die Kontoentwicklungs App wird oft installiert und wir haben das Feedback bekommen, dass besonders der monatliche Upload der Kontoauszüge als mühsam empfunden wird. In diesem Blogpost stellen wir daher den automatisierten Kontodownload vor.
Die hier vorgestellte Funktion zum automatischen Kontodownload ist noch ein Prototyp und verlangt einige technische Grundkenntnisse für die Verwendung: die Ausführung eines Docker Containers und das Einrichten eines Cron-Jobs. In der endgültigen Form, wird die Einrichtung aber natürlich in der Kontoentwicklungs-App als optionale Datenquelle möglich sein.
Die Konfiguration für den automatisierten Kontodownload wird als JSON bereitgestellt und umfasst folgende 3 Bereiche:
credentials.json
{
"bank": "easybank",
"username": "123456",
"password": "12345geheim",
"account": "AT121420020010123456"
}
Warnung: Speichere diese Daten nur auf deinem eigenen (vetrauenswürdigen) Computer und stelle sicher, dass die Zugangsdaten zu deinem Bankkonto niemals öffentlich werden! Wir haben bei der Entwicklung größtmögliche Sorgfalt angewendet, und durch die Verwendung von Docker, werden deine Zugangsdaten auch nur temporär verwendet, bevor sie mit dem Container nach der Ausführung wieder entfernt werden.
balance.json
{
"url": "http://1.2.3.4:8080/",
"key": "eu.ownyourdata.bank",
"secret": "1234567890AaBbCcDdEe",
"repo": "eu.ownyourdata.bank.reference",
"partial": "balance",
"delete": "all",
"map":[
{ "date": "date" },
{ "value": "balance" }
]
}
bookings.json
{
"url": "http://1.2.3.4:8080/",
"key": "eu.ownyourdata.bank",
"secret": "1234567890AaBbCcDdEe",
"repo": "eu.ownyourdata.bank",
"partial": "bookings",
"merge":[
"date",
"value",
"descriptionOrig"
],
"map":[
{ "date": "date" },
{ "description": "description" },
{ "descriptionOrig": "other|original" },
{ "value": "amount" }
]
}
Mit Hilfe dieser Konfiguration können nun Referenzwert und Umsätze mit folgendem Skript (z.B. import.sh) importiert werden:
#!/bin/bash
# read Easybank balance
cat /path/to/credentials.json | \
docker run -i --rm oydeu/srv-bank /bin/run.sh | \
docker run -i --rm oydeu/srv-pia_write /bin/run.sh \
"$(cat /path/to/balance.json | tr -d '\040\011\012')"
# Import Easybank
cat /path/to/credentials.json | \
docker run -i --rm oydeu/srv-bank /bin/run.sh | \
docker run -i --rm oydeu/srv-pia_write /bin/run.sh \
"$(cat /path/to/bookings.json | tr -d '\040\011\012')"
Damit dieses Skript täglich ausgeführt wird, muss noch ein Cron-Job definiert werden:
0 2 * * * root /path/to/import.sh
Die notwendigen Docker-Images sind auf dockerhub.com und die Sourcen auf github.com verfügbar:
Derzeit können Daten von Easybank und ING-DiBa automatisiert heruntergealden werden. Kontaktiere uns, wenn du ein Konto bei einer anderen Bank hast und ebenfalls deine Umsätze automatisiert sammeln möchtest.
 Diese Woche (21.-25. August) habe ich an der 3. Keystone Training School teilgenommen und das Thema war Keyword search in Big Linked Data: Es gab spannende Vorträge, interessante Teilnehmer und unser Team hat den Hackathon am Freitag überragend gewonnen 🙂 . Linked Data war für mich bisher ein obskurer Begriff der etwas mit dem semantischen Web zu tun hat, aber genau konnte ich es nicht einordnen. Das hat sich diese Woche grundlegend geändert und ich glaube auch für OwnYourData ergeben sich daraus wichtige Möglichkeiten zur Weiterentwicklung.
Diese Woche (21.-25. August) habe ich an der 3. Keystone Training School teilgenommen und das Thema war Keyword search in Big Linked Data: Es gab spannende Vorträge, interessante Teilnehmer und unser Team hat den Hackathon am Freitag überragend gewonnen 🙂 . Linked Data war für mich bisher ein obskurer Begriff der etwas mit dem semantischen Web zu tun hat, aber genau konnte ich es nicht einordnen. Das hat sich diese Woche grundlegend geändert und ich glaube auch für OwnYourData ergeben sich daraus wichtige Möglichkeiten zur Weiterentwicklung.
Das erste Mal beschäftigte ich mich mit dem semantischen Web 2006-07. Ziel des semantischen Webs war es, Informationen im Internet für Maschinen lesbar zu machen. Ein Beispiel: Wenn wir die Wikipedia-Seite von Wien lesen, finden wir schnell heraus dass Wien derzeit knapp 1,9 Mio Einwohner hat. Diese Information aber für Maschinen zugänglich zu machen und Vergleiche anzustellen (z.B. hat Oslo oder Wien mehr Einwohner?) war dagegen sehr schwierig. Das semantische Web sollte nun alle Informationen kategorisieren und verarbeitbar machen.
In dem Forschungsprojekt an dem ich damals teilnahm ging es um die Beschreibung von Zusammenhängen in der Flugdomäne und wir entwickelten Ontologien, „pferchten“ die vorhanden Daten in dieses semantische Korsett und erhofften uns neue Erkenntnisse. Nichts davon traf aber ein und ich glaube alle waren damals froh, als das Projekt vorüber war: außer ein paar vielversprechender akademischer Papers war für mich kein praktischer Nutzen erkennbar.
 In den letzten 10 Jahren gab es aber in diesem Bereich wichtige Weiterentwicklungen: SPARQL als universelle Abfrage- und Manipulations-Sprache wurde vom W3C etabliert und es ist nun möglich unterschiedlichste semantisch beschriebene Datenquellen einheitlich abzufragen und ggf. auch zu bearbeiten (vergleichbar mit SQL bei Datenbanken). Der Vergleich ob Wien mehr Einwohner als Oslo hat, lässt sich in SPARQL so formulieren:
In den letzten 10 Jahren gab es aber in diesem Bereich wichtige Weiterentwicklungen: SPARQL als universelle Abfrage- und Manipulations-Sprache wurde vom W3C etabliert und es ist nun möglich unterschiedlichste semantisch beschriebene Datenquellen einheitlich abzufragen und ggf. auch zu bearbeiten (vergleichbar mit SQL bei Datenbanken). Der Vergleich ob Wien mehr Einwohner als Oslo hat, lässt sich in SPARQL so formulieren:
ASK {
<http://dbpedia.org/resource/Vienna\> dbo:populationTotal ?x .
<http://dbpedia.org/resource/Oslo\> dbo:populationTotal ?y .
FILTER(?x > ?y) .
}
Das Statement kann man hier eingeben und erhält dann dieses Ergebnis .
Außerdem lockerte man auch die Anforderungen zur semantischen Beschreibung von Daten: Anstatt komplizierte Ontologien zu entwerfen denen alle erfassten Daten streng entsprechen mussten, verfolgt Link Data „nur mehr“ das Ziel maschinenlesbare Attribute zu verwenden, die auch selbst definiert werden können – eine genauere Definition gibt’s hier. Tim Berners-Lee, Vater des semantischen Webs, beschrieb diesen pragmatischen Ansatz mit den Worten:
Linked Data is the Semantic Web done right.
Was bedeutet das nun für OwnYourData? Bisher ist der Datentresor als persönliches Archiv der eigenen Daten dafür ausgelegt, dass Apps via OAuth2 darauf zugreifen. D.h. es gibt ein vordefiniertes Datenformat (beschrieben auf Github bei den einzelnen Apps) und jegliche Datenquellen oder Visualisierungen, müssen sich daran halten. Zur Speicherung von Temperaturwerten in einem Raum sieht ein Datensatz als Beispiel so aus:
{"id":106920,"value":23.91,"timestamp":1502019600}
Diese Speicherung ist sehr effizient, hat aber auch einige Nachteile – insbesondere der fehlende Kontext:
value? – auch hier muss ein Entwickler in der Dokumentation nachlesen, um das herauszufindenLinked Data würde den Datensatz so beschreiben (als Format wird hier JSON-LD verwendet, es gibt aber zahlreiche andere Alternativen):
{
"@context": "http://schema.org",
"@type": "MeasureAction",
"sensor": "https://chris.datentresor.org/sensor/library_temperature",
"location": "Bibliothek",
"dateCreated": "2017-08-25T19:30",
"measurement": {
"@type": "temperature",
"value": "23.5",
"unit": "Celsius"
}
}
Diese semantische Annotation erlaubt nun eine eindeutige Beschreibung der gesammelten Daten, die auch von Software interpretierbar ist. Möchte man Daten mit anderen teilen, kann leicht (= automatisiert) herausgefunden werden, ob relevante Informationen verfügbar sind und wenn ja, können sie auch zwischen verschiedenen Formaten konvertiert werden. Unter Zuhilfenahme der Linking Open Data Community sind völlig neue Anwendungsfelder denkbar und eine inzwischen weit verbreitete Anwendung sind sogenannte Knowledge Graphen.
 Diese beschreiben meist Instanzen (zB Stadt Wien) samt Verlinkungen von Attributen (zB Einwohnerzahl) und stellen diese übersichtlich in Infoboxen dar. Bekannt sind diese Knowledge Graphen vor allem von den Suchergebnissen bei Google, wo sie Informationen zu berühmten Persönlichkeiten, Sehenswürdigkeiten oder Unternehmen in einer Box neben den Suchergebnissen anzeigen. Oder auch in Wikipedia wo beispielsweise Informationen zu Städtenrechts am Beginn eines Artikels dargestellt sind – diese Information ist dann übrigens als Linked Data via DBpedia verfügbar.
Diese beschreiben meist Instanzen (zB Stadt Wien) samt Verlinkungen von Attributen (zB Einwohnerzahl) und stellen diese übersichtlich in Infoboxen dar. Bekannt sind diese Knowledge Graphen vor allem von den Suchergebnissen bei Google, wo sie Informationen zu berühmten Persönlichkeiten, Sehenswürdigkeiten oder Unternehmen in einer Box neben den Suchergebnissen anzeigen. Oder auch in Wikipedia wo beispielsweise Informationen zu Städtenrechts am Beginn eines Artikels dargestellt sind – diese Information ist dann übrigens als Linked Data via DBpedia verfügbar.
Als Ausblick für OwnYourData: ein solcher Knowledge Graph könnte mit den selbst gesammelten Daten dargestellt werden – siehe Kasten daneben. Falls du das spannend findest oder auch eigene Ideen für die Auswertung eigener Daten mit semantischer Annotation hast, schreib uns ein Email oder hinterlasse einen Kommentar unter diesem Artikel!
 Seit einer Woche habe ich ein NAS (Synology DS1517+) und ein für mich besonders interessantes Feature ist die Möglichkeit darauf Docker-Container auszuführen. Gleichzeitig hat unser Jüngster (2½ Jahre alt) nun sein eigenes Zimmer und ich wollte wissen, ob er dort auch wirklich durchschläft. Unsere Freunde von Gonimo.com haben einen tollen Online-Babymonitor entwickelt und sogar ein eigenes Feature für uns eingebaut, um den gemessen Geräuschpegel in einem OwnYourData Datentresor mitzuprotokollieren. Zur Visualisierung der gesammelten Daten gibt es die OYD-Gonimo App und in diesem Blogpost beschreibe ich das Setup, um in der Nacht den Geräuschlevel im Schlafzimmer unseres Sohnes mit einem Android-Phone zu messen und im Datentresor aufzuzeichnen.
Seit einer Woche habe ich ein NAS (Synology DS1517+) und ein für mich besonders interessantes Feature ist die Möglichkeit darauf Docker-Container auszuführen. Gleichzeitig hat unser Jüngster (2½ Jahre alt) nun sein eigenes Zimmer und ich wollte wissen, ob er dort auch wirklich durchschläft. Unsere Freunde von Gonimo.com haben einen tollen Online-Babymonitor entwickelt und sogar ein eigenes Feature für uns eingebaut, um den gemessen Geräuschpegel in einem OwnYourData Datentresor mitzuprotokollieren. Zur Visualisierung der gesammelten Daten gibt es die OYD-Gonimo App und in diesem Blogpost beschreibe ich das Setup, um in der Nacht den Geräuschlevel im Schlafzimmer unseres Sohnes mit einem Android-Phone zu messen und im Datentresor aufzuzeichnen.
Folgende Komponenten verwende ich dafür:
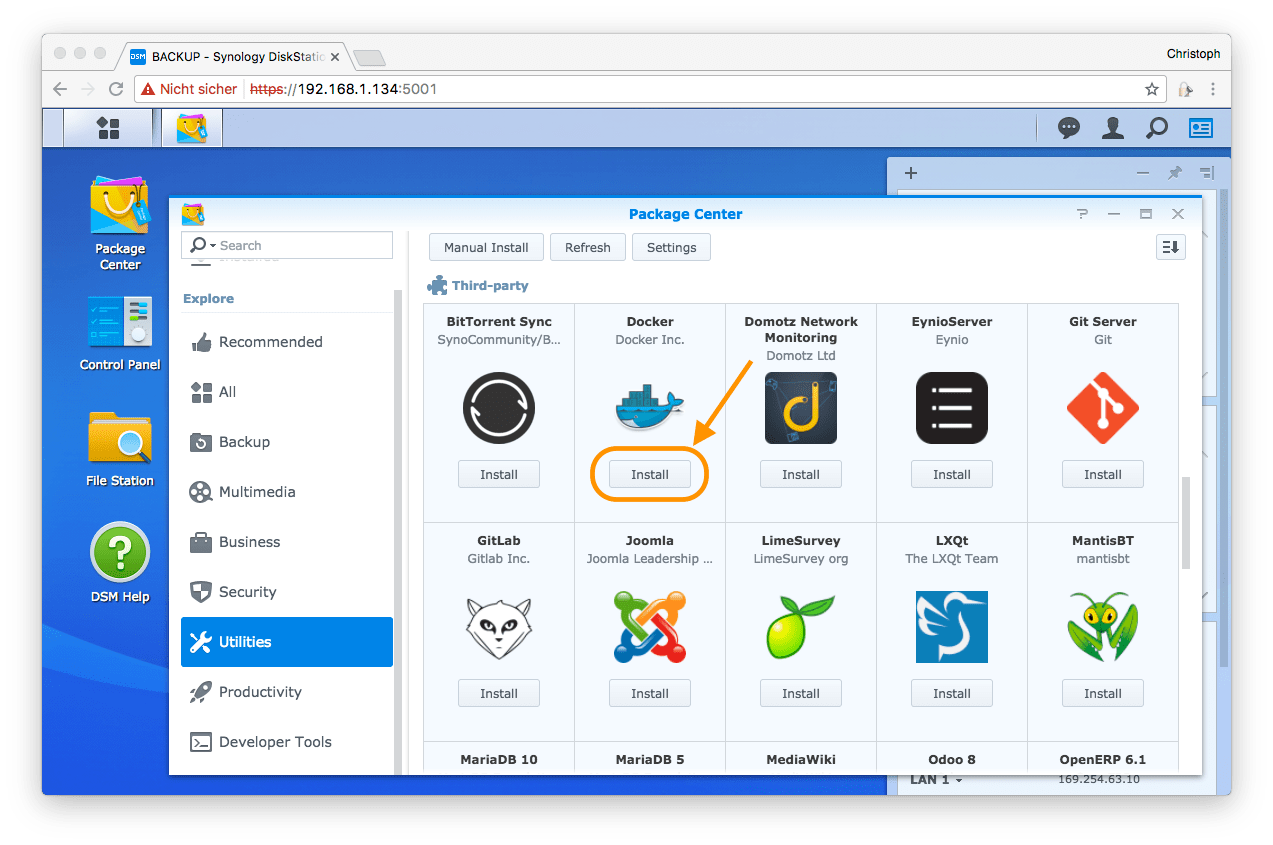
Als erstes muss Docker installiert werden. Dazu öffne ich den DiskStation Manager (DSM) der Synology im Browser und gehe ins Package Center. Unter Utilities > Third-party findet sich ein Eintrag von Docker und dort klicke ich auf Install.
Als nächstes starte ich Docker und unter Image lade ich folgende 2 Images herunter:
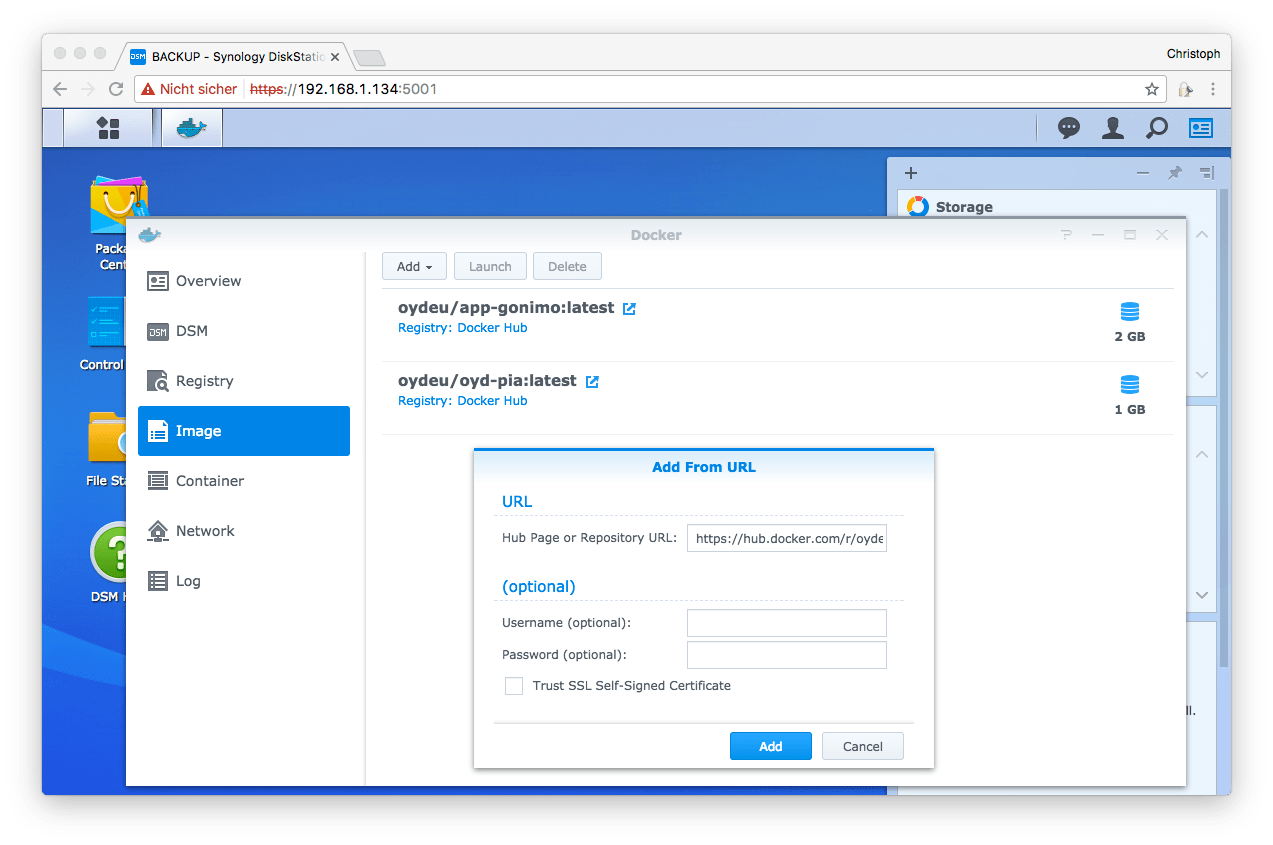
Sind die beiden Images heruntergeladen, wähle ich sie jeweils aus und klicke auf Launch, um sie zu starten.
Als nächstes öffnen wir den Datentresor und die OYD-Gonimo App. Dazu muss ich den vergebenen Port herausfinden, der unter Container > {Auswahl} > Details > Local Port angegeben ist.

In meinem Fall sind die Adressen:
Als erstes öffne ich den Datentresor (Username: admin, Password: admin) und registriere dort die OYD-Gonimo App:

Standardmäßig werden Apps unter der Onlineadresse https://{app}.oydapp.org ausgeführt. Für sensible Daten möchte ich, dass aber nicht nur die Daten, sondern auch die Visualisierung bei mir daheim ausgeführt wird. Daher kopiere ich die Link-Adresse die bei Open angezeigt wird und ändere sie, sodass ich die OYD-Gonimo App auf der Synology aufrufen kann.

Die ursprüngliche Adresse war bei mir:
https://gonimo.oydapp.eu/?PIA_URL=http%3A%2F%2F192.168.1.134%3A32769&APP_KEY=eu.ownyourdata.gonimo&APP_SECRET=AiJ2n10RhqGLdBE24uOg
und den ersten Teil https://gonimo.oydapp.eu/ ändere ich auf die oben notierte Adresse der OYD-Gonimo App:
http://192.168.1.134:32768/?PIA_URL=http%3A%2F%2F192.168.1.134%3A32769&APP_KEY=eu.ownyourdata.gonimo&APP_SECRET=AiJ2n10RhqGLdBE24uOg
Die so erstellte Adresse füge ich nun in die Adressleiste meines Browsers ein und öffne die OYD-Gonimo App. Dort gehe ich auf die Seite Datenquellen und kopiere mir den Befehl, um den Online Babymonitor Gonimo.com für die Speicherung der Daten in meinen Datentresor zu konfigurieren.
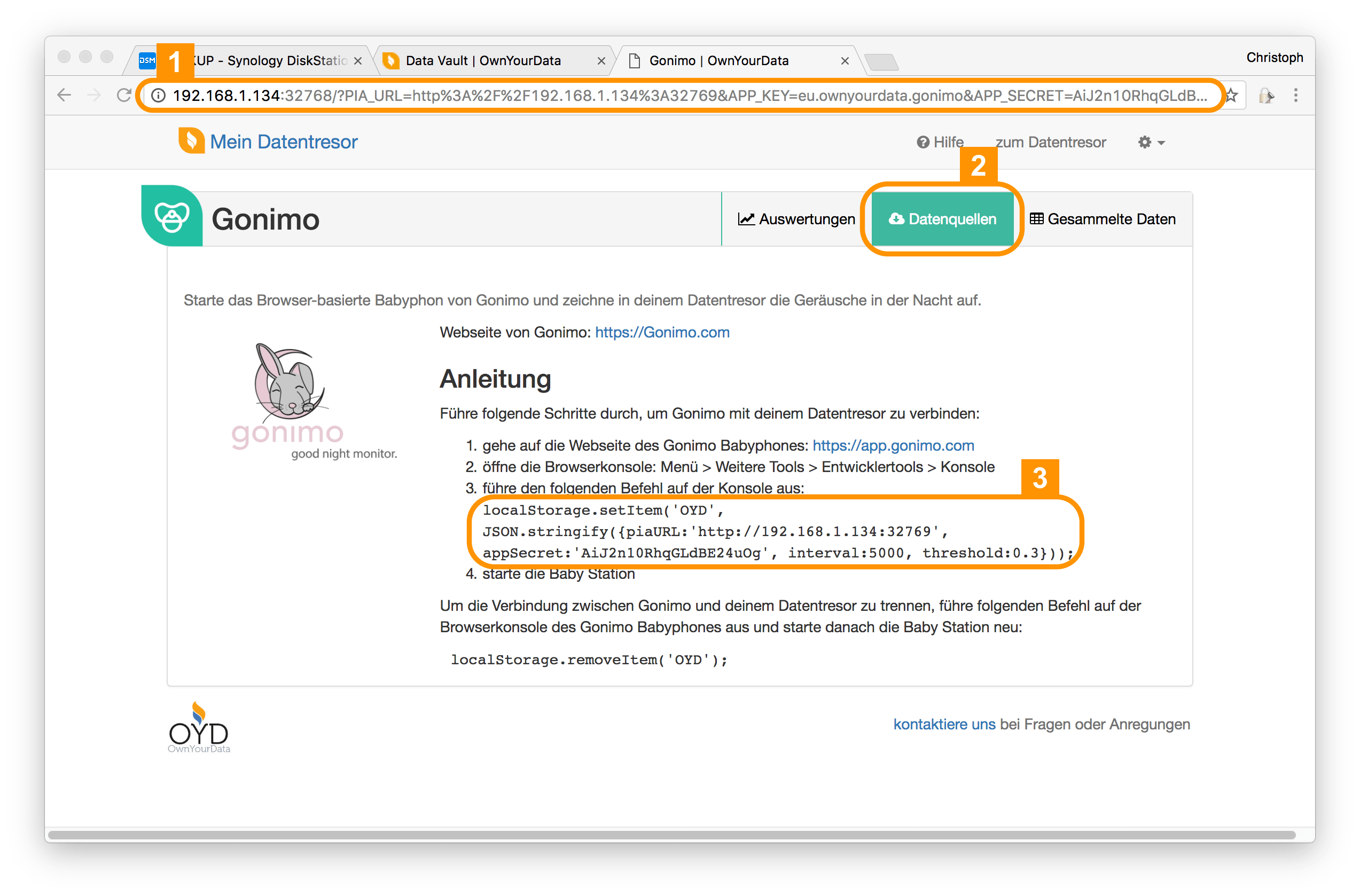
In diesem Schritt müssen nun einige Konfigurationen vorgenommen werden, damit sich die Gonimo.com Webapp auf einem Android Handy mit dem OwnYourData Datentresor verbinden kann. (iOS Devices werden derzeit leider noch nicht unterstützt, sollen dann aber mit Safari in iOS 11 funktionieren.)
Dazu richte ich zuerst einen Reverse Proxy ein, damit der Datentresor über https erreichbar ist. Im Control Panel unter Application Portal > Reverse Proxy lege ich einen Eintrag wie im Screenshot unten dargestellt an. Der Hostname unter Destination muss dabei natürlich mit der eigenen IP Adresse ersetzt werden.

Damit ist der Datentresor nun unter https://{lokale Synology IP}:8080 erreichbar.
Den Schritt zum Einrichten eines Zertifikats musste ich nachträglich einfügen, da der Browser des (bereits alten) Android Smartphones das Default-Zertifikat von Synology nicht akzeptiert hat. (Ein Test am Desktop mit einem aktuellen Chrome Bowser (v59) hat das Zertifikat anstandslos akzeptiert.)
Dazu gehe ich im Control Panel auf Security > Certificate und erstelle mit Add ein neues Self-signed Certificate für die verwendete IP Adresse. Mit Configure weise ich dann dem Port 8080 dieses Zertifikat zu.

Jetzt verbinde ich das Android Smartphone mit meinem PC via USB und öffne am Smartphone im Chrome Browser die Seite „https://app.gonimo.com“. Am PC öffne ich ebenfalls den Chrome Browser und dort die Entwicklertools > Remote devices > das via USB verbundene Smartphone > den apps.gonimo.com Tab > Inspect > Console und füge den aus Schritt 3 Datentresor und OYD-Gonimo App starten kopierten Befehl der OYD-Gonimo App > Datenquellen kopierten Befehl ein.

Anmerkung: das Mikrofon des Alcatel One Touch benötigt einen geringeren Schwellenwert, damit es bei Geräuschen anschlägt; ich habe daher im eingefügten Befehl den Wert für threshold von 0.3 auf 0.01 reduziert.
Nachdem dieser Wert für die Webseite gesetzt ist, klicke ich am Smartphone auf Baby und dann Start. Man kann das Smartphone nun vom PC trennen und zum Beispiel ins Kinderzimmer legen. Die Webseite schickt ab jetzt immer, wenn in einem 5 Sekunden Intervall ein Geräuschpegel größer als 0.01 erreicht wird, eine Nachricht mit dem aktuellen Zeitstempel und dem Geräuschpegel an den Datentresor. Am nächsten Morgen schließt man die Webseite im Browser und damit stoppt die Aufzeichnung. Bei der nächsten Verwendung muss man nur mehr die Webseite am Smartphone öffnen – keine Verbindung via USB und setzen der Werte ist mehr notwendig, da alle Informationen im Local Storage der Webseite gespeichert bleiben.
Am nächsten Morgen kann ich dann die Aufzeichnungen in der OYD-Gonimo App betrachten. Ich öffne dazu die OYD-App unter der Adresse die ich im Schritt 3 Datentresor und OYD-Gonimo App starten erstellt habe und sehe unter Auswertungen den Verlauf des Geräuschpegels in der Nacht.

Er ist um 8 Uhr eingeschlafen, hatte ein ruhige Nacht, aber bald nach 5 Uhr früh sind er und seine Brüder aufgewacht…
Mit dem hier beschriebenen Setup habe ich ein zusätzliches Anwendungsfeld für meine Synology beschrieben. Zugegeben ist die Installation für Endanwender im Moment zu schwierig, und in Zukunft möchte ich daher OwnYourData als eigene App im Synology Package Center anbieten. Die Installation soll dann so einfach wie jede andere Anwendung sein und mit einem einzigen Klick erfolgen. Falls dich das interessiert und du bestimmte Apps schon vorab verwenden möchtest, schreib mir ein Email oder hinterlasse einen Kommentar unter diesem Artikel!

![]()
![]()

{kind=link}