Latest News
Updates from the OwnYourData team.
Updates from the OwnYourData team.
OwnYourData & Human Colossus Foundation have been selected for the 2nd phase in the Data Portability & Services Incubator (DAPSI) to continue development of the Digital Immunization Passport project. From September 2020 to January 2021 we developed the first version of a Digital Immunization Passport for Yellow Fever and demonstrated the feasability of such a […]
In the DECTS project – funded by NGI TRUST Grant Agreement No. 825618 – OwnYourData and DEC112 implemented a Proof-of-Concept to demonstrate sharing personal data between an emergency caller and a control room. Read more

OwnYourData and the Human Colossus Foundation have been selected to take part in the Data Portability & Services Incubator (DAPSI), a 3-year EU funded project that empowers internet innovators to develop new solutions in the data portability field.
The Data Portability and Services Incubator (DAPSI) is a EU funded project, under the European Commission’s Next Generation Internet (NGI) initiative, to empower top internet innovators to develop human-centric solutions, addressing the challenge of personal data portability on the internet, as foreseen under the GDPR and make it significantly easier for citizens to have any data which is stored with one service provider transmitted directly to another provider.
DAPSI will support top-notch projects through a 9-month incubation programme where experts in diverse fields will provide a successful working methodology, access to top infrastructure, training in business and data related topics, coaching, mentoring, and a vibrant ecosystem. On top of that, each DAPSI project can receive up to €150k equity-free funding.
Digital Immunization Passport (DIP) is taking part in DAPSI to create a state-of-the-art digital certificate of vaccination. Currently, vaccination and immunization information are spread over different organizations like labs and hospitals as well as pharmaceutical companies together with government agencies. A patient usually only has a paper certificate that provides vaccination treatments with often difficult to read handwritten additional information. In the proposed solution OwnYourData and Human Colossus Foundation will develop an end-to-end data flow that:
The main focus of this project is on Data Interoperability & Compatibility through establishing interfaces between health industry and individuals as well as pushing forward on standardized interfaces for PDSs. Additionally, we address Data Transparency (Usage Policies and Data Provenance in Semantic Containers) and Security & Privacy (by applying blockchain technology and digital watermarking on data sharing).
In the two-phase supporting programme, the projects will develop advanced solutions in the Data Portability field. From September 2020 to February 2021 (Kick-Start phase) they will develop a solution related to a specific use case. The best projects will progress to the second phase (Booster) where the use cases will be fostered to evolve into solid projects to gain enough traction for deployment and get ready for the market.
Take a look at the DAPSI project portfolio to see more information about the selected innovators. The Digital Immunization Passport page is available here.
To read more about DAPSI, please visit the website: dapsi.ngi.eu
![]() A bold new initiative to shape the new normal of data has arrived – MyData Operator 2020 status awarded to OwnYourData.
A bold new initiative to shape the new normal of data has arrived – MyData Operator 2020 status awarded to OwnYourData.
In July 2020, OwnYourData was awarded the inaugural status of MyData Operator 2020. The award was given to 16 world-leading organisations from 12 countries, all working for humans-centric approaches to personal data.
A MyData operator, as described in the white paper Understanding MyData Operators, is a provider of infrastructure for personal data management and a key element in creating sustainable ecosystems for fair and ethical use of personal data. MyData operators provide interoperability at the technical, informational and governance levels to support the flow of personal data across services. They are examples of a human-centric approach to what the recent EU data strategy calls “novel data intermediaries” and which are set to play a critical role in the provision of the strategy’s vision of data spaces.
Radical collaboration for human-centric data control
The awarded organisations are working together with their competitors on areas of mutual interest to create a successful, interoperable personal data ecosystem. “MyData Global congratulates awardees for their integrity, dedication, and openness in this unprecedented sharing of information that goes far beyond the requirements of any regulation. Ultimately, it is individuals who will benefit from this shared understanding of MyData operators – with increased transparency, better choices, and more innovative, responsible services,” explains Joss Langford, co-lead of the MyData Operators Thematic Group and the lead editor for Understanding MyData Operators white paper.
More information
The organisations awarded the MyData Operator 2020 status are listed here: mydata.org/operators/
The MyData Operator 2020 Award was created by the internationally recognised nonprofit MyData Global. The award acknowledges organisations that place the individual at the centre of personal data about them, provide tools to help them manage personal data, and have the individual as the primary beneficiary of this data.

In the NGI funded MyPCH project OwnYourData developed several technologies for secure and traceable data exchange of diabetes data: Digital Watermarking, Semantic Annotation, and Data Traceability. In addition, we also participated in a MyData Health initiative to write a feature article for the European Medical Writers Association (EMWA) and we are proud to announce that the article written by 14 individuals from 9 countries around the 6 MyData principles is already published and public available via the EMWA journal website – see section “Data Interoperability” and “Establishing trust between stakeholders for health data use” for example use cases of Semantic Containers.
In this blog post we cover the successful integration of diabetes data into the OwnYourData Data Vault. In this data flow, persons with diabetes (Pwd) can not only transfer their data to a Personal Data Store but also perform SPARQL queries to combine their diabetes data with public information – more information and examples are available here.
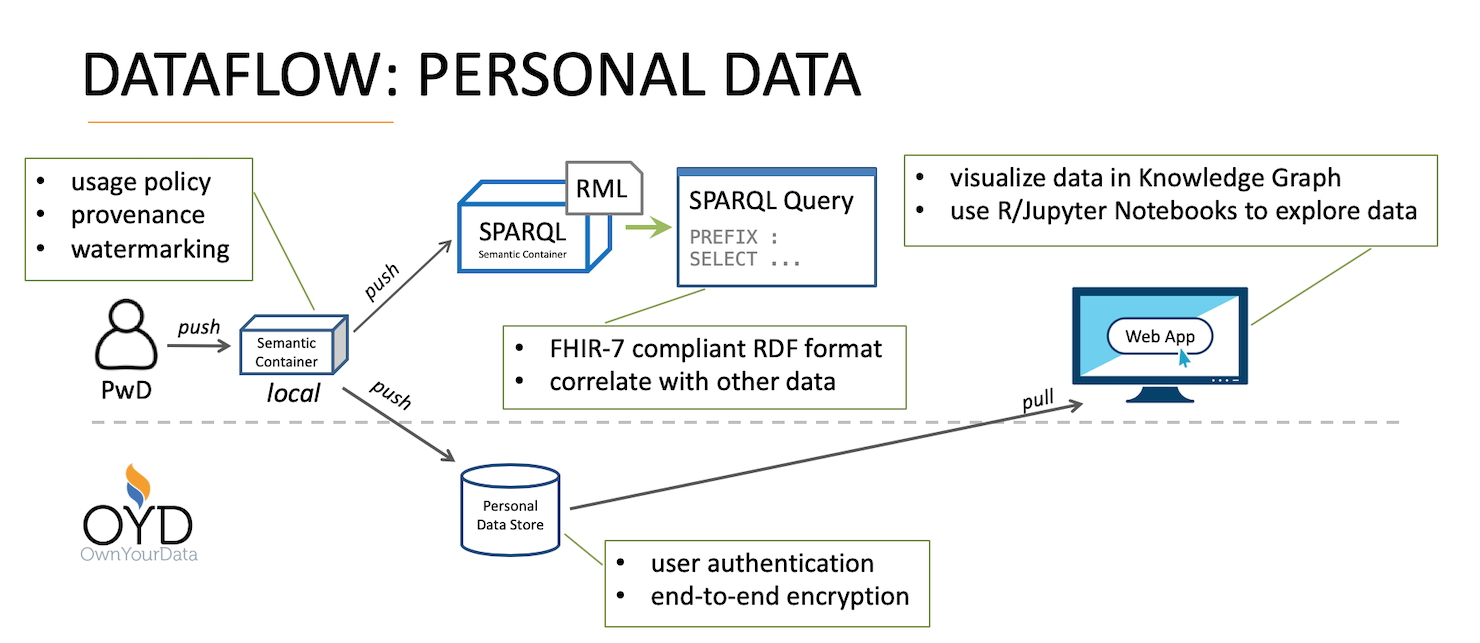
A special feature in the OwnYourData Data Vault is the Personal Knowledge Graph shown on the left side of the main screen. It compiles available data from the respective user and presents the information in a clear form. The screenshot below shows information about recent GPS Data, blood sugar levels over the course of a few days, as well as record numbers overall.
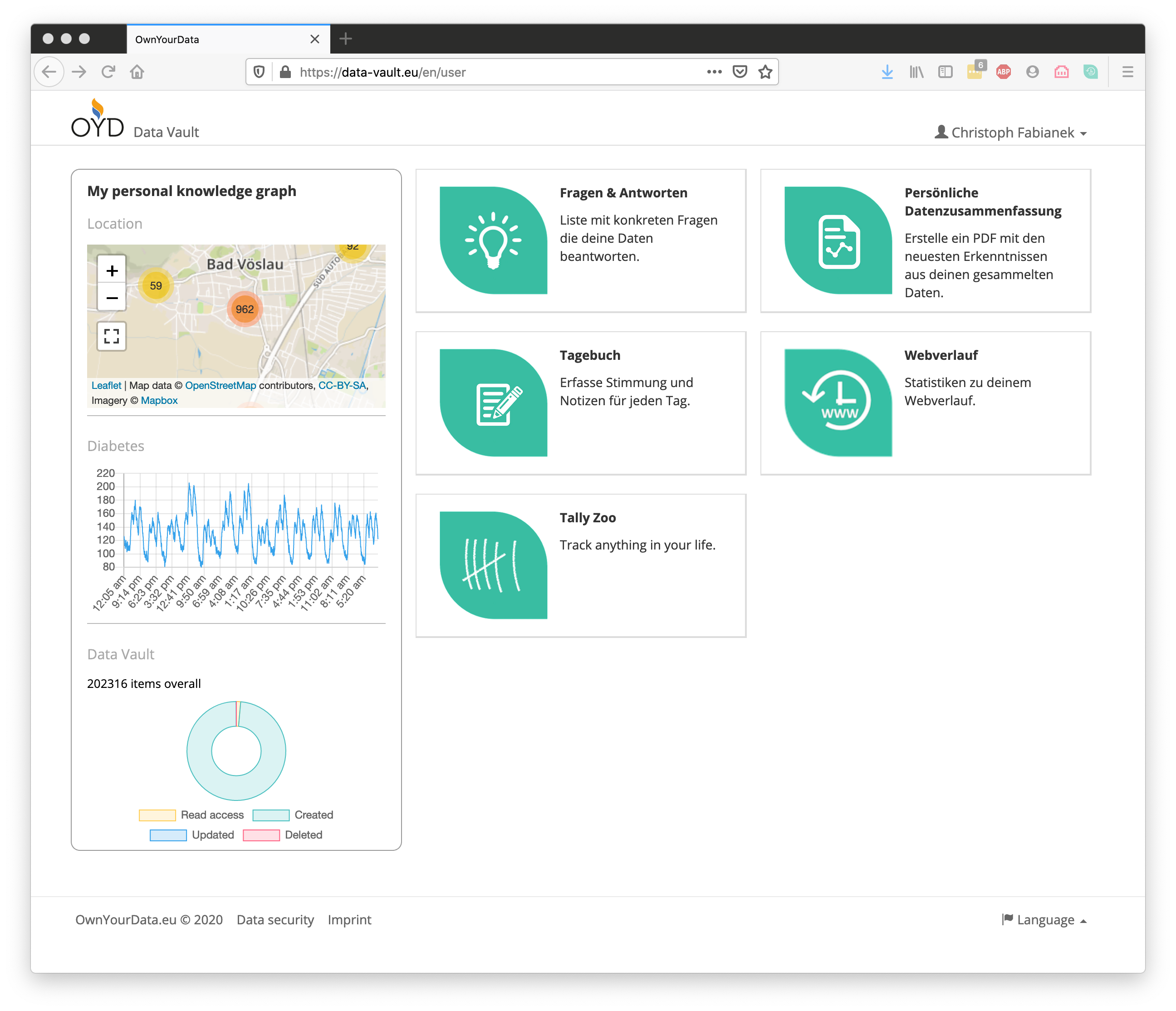
Beyond information in the Personal Knowledge Graph plugins allow further data exploration. In the course of the MyPCH project however, we decided to use existing tools like R or Jupyter Notebooks to provide more sophisticated visualization and analysis mechanisms. The R-Notebook available on Github is an example how to retrieve and decrypt information in the Data Vault and compile a report.
If you have any questions using Diabetes data with Semantic Containers or within the OwnYourData Data Vault don’t hesitate to contact us as support@ownyourdata.eu.
The project DECTS (Deaf Emergency Chat and Training System) aims to provide deaf emergency calls and a training environment in several languages. With the help of a chatbot, deaf people can learn how to use the app and at the same time generate test data for training the control center personnel. The users can determine whether the entries are used as test data and there is documentation about origin, GDPR-compliant provision, and use of the data. The consent to the use of the data can also be changed and revoked later.
The teams from OwnYourData and DEC112 work together to implement this. In previous projects, an infrastructure was already set up in Austria for deaf emergency calls and the challenge now lies in international operations – for example when an Austrian tourist is on vacation in Copenhagen: in this case an emergency call is made via the DEC112 App registered in Austria and conveyed to the control center in Copenhagen.
A chatbot is developed for the training environment that simulates a control center. In a test chat, structured information is queried and further questions arise when using certain keywords. In cooperation with emergency call centers, typical conversations were analyzed and so-called decision trees were created, which the chatbot automatically processes.
If a user consents to the further use of the chat protocol, this consent can be managed in the OwnYourData Data Vault. There the consent of the transfer of the data is documented and it is possible to query when the data was accessed. In particular, however, access can also be restricted or subsequently prohibited. Semantic containers are used as the technology platform, which ensure data access is transparent and traceable.
Finally, personal data (emergency contacts, medical data and other information) can also be stored in the OwnYourData Data Vault, which is automatically provided to the control center in the event of an emergency chat. This personal data is referenced using a DID (Decentralized ID) and the data itself is stored encrypted. The Shamir’s Secret Sharing scheme ensures that the data can only be read by the user and the control center, but cannot be accessed by OwnYourData or DEC112.
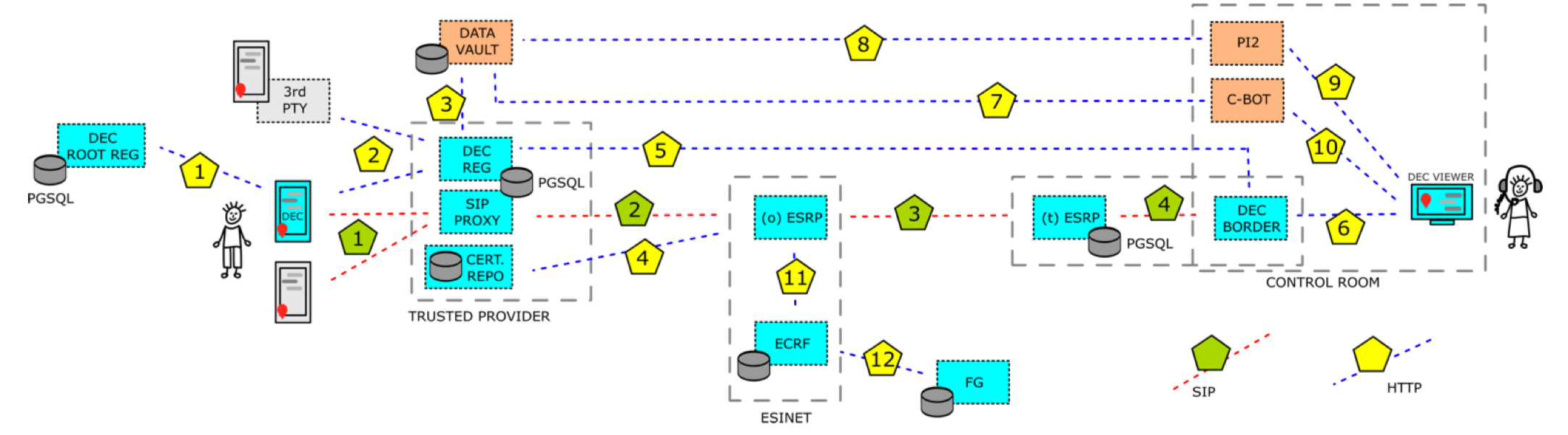
The system architecture for the project is shown in the graphic below, together with the data flows between the individual components. All parts are now at least available as prototypes and the first end-to-end tests were carried out in May.

![]()
![]()
